
Ring Attention 技术克服 GPU 内存瓶颈
现阶段 AI 无法处理大量数据输入,ChatGPT 最多提取数千个单词,然而 Google DeepMind 研究人员已经找到新方法克服问题

ChatGPT 目前最多可以提取数千个单词,更大的 AI 模型如 Claude 2 能够处理更多数据。由于训练和运算 AI 模型的 GPU 记忆体限制,现阶段无法处理大量数据输入,然而 Google DeepMind 研究人员已经找到新方法克服问题。
Google DeepMind 一名研究人员 Hao Liu 以及新创公司 Databricks 技术长 Matei Zaharia、加州大学柏克莱分校教授 Pieter Abbeel 近日发表论文《 Ring Attention with Blockwise Transformers for Near-Infinite Context》。
揭晓一种帮助 AI 模型输入更多数据的新方法,名为 Ring Attention 可消除 AI 模型运算的记忆体瓶颈,将数百万个单词输入 AI 模型进行运算。
在讨论 AI 聊天机器人及其背后大型语言模型运算前,可先了解 token 以及输入文字提示的 context window。token 是 AI 模型处理和产生文字的基本单位,可以代表一个单词或一个单词的一部分。
通常 AI 模型开发商会透露支持多少 token 的上下文长度。context window 则是人们将问题、文字提示输入 AI 模型的空间,分析处理后给予文字、表格等内容回复。
举例来说,OpenAI GPT-3.5 模型的上下文长度为 16K token,GPT-4 模型则是 32K token。新创公司 Anthropic 的聊天机器人 Claude 2,支持多达 100K token 上下文长度,相当于大约 75,000 个单词,已经是一本书的文字量。
Hao Liu 提出的概念考量到,现代 AI 模型处理数据的方式需要 GPU 储存内部输出,数据传递到下一个 GPU 计算在重新运算,这需要大量内存,但实际上 GPU 内存不足以应付,限制 AI 模型能够处理的数据量,无论 GPU 效能有多高,都存在这种内存瓶颈。
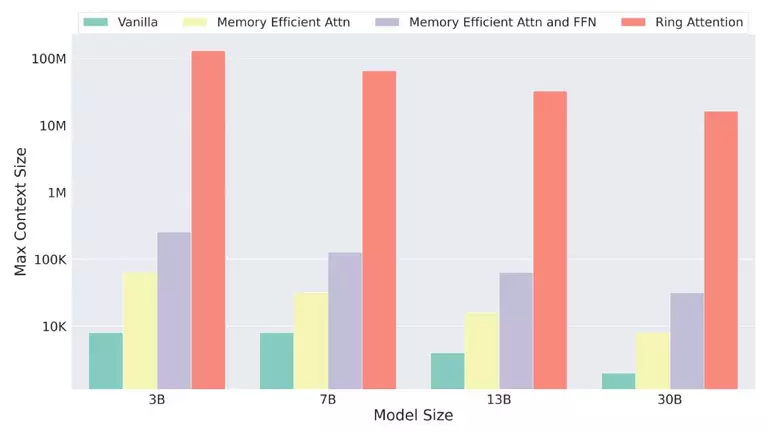
然而 Ring Attention 形成一种环状 GPU,将处理位元传递到下一个 GPU,同时从其他邻近 GPU 接收类似区块,以此不断重复。这有效消除各个设备施加的内存限制,论文对此解释。
这代表人们应该能将数百万个单词输入 AI 模型的 context window,不再只有数万个单词。理论上,未来许多书籍甚至许多影片可以一次输入 context window,由 AI 模型加以分析。
按照目前做法,如果有一个 16K token 的 context window,以及依靠 256 个 NVIDIA A100 GPU 的 130B 参数 AI 模型,上下文长度仅限 16K token。然而透过 Ring Attention 技术,相同前提可以处理多达 4,000K token。
Hao Liu 提出的想法是原始 Transformer 架构翻版,Transformer 模型自 2017 年推出后彻底改变 AI 发展,成为 ChatGPT 以及近年来所有AI 模型的基础,例如 GPT-4、 Llama 2 或者 Google 计划推出的 Gemini。
与此同时值得思考的是,透过 Ring Attention 技术是否可以运用更少 GPU 处理更多AI 工作负载,是否也意味着对 NVIDIA GPU 需求能够进一步减缓。
Ring Attention 不会阻碍 GPU 销售,Hao Liu 否认这样的论点,并认为科技公司和开发商运用新技术,对于发展大型语言模型能有更大胆的想像。




