Google 推出视频生成模型 VideoPoet
为探索语言模型在视频生成领域的应用,Google 推出大型语言模型 VideoPoet,能够执行包括文字转成视频、图片转成视频、视频生成语音等五大功能
近来一个个视频生成模型出现,无论是贴近提示要求或在视频处理细节上,许多情况下展现出令人惊艳的高品质。Google 也不甘示弱,日前发表自主开发的大型语言模型 VideoPoet。
为了探索语言模型在视频生成中的应用,Google 引进全新大型语言模型 VideoPoet,能够执行包括文字转成视频、图片转成视频、视频风格转换、视频修复、视频生成语音等五大功能,而且预设直接产生短视频影音。
比方说,用户输入文字提示「两只熊猫打扑克牌」,VideoPoet 生成两只熊猫坐在桌边打扑克牌的短视频。图片转成视频方面,像是上传一张油画图片,画中一艘航向大海的船遭遇雷电交加、波涛汹涌的大浪,使用 VideoPoet 可以转变成动图型态。
VideoPoet 也能为视频生成语音,例如先以模型产生 2 秒短片,并尝试在没有任何文字提示下配上语音,于是从单一模型就能产生视频和语音。
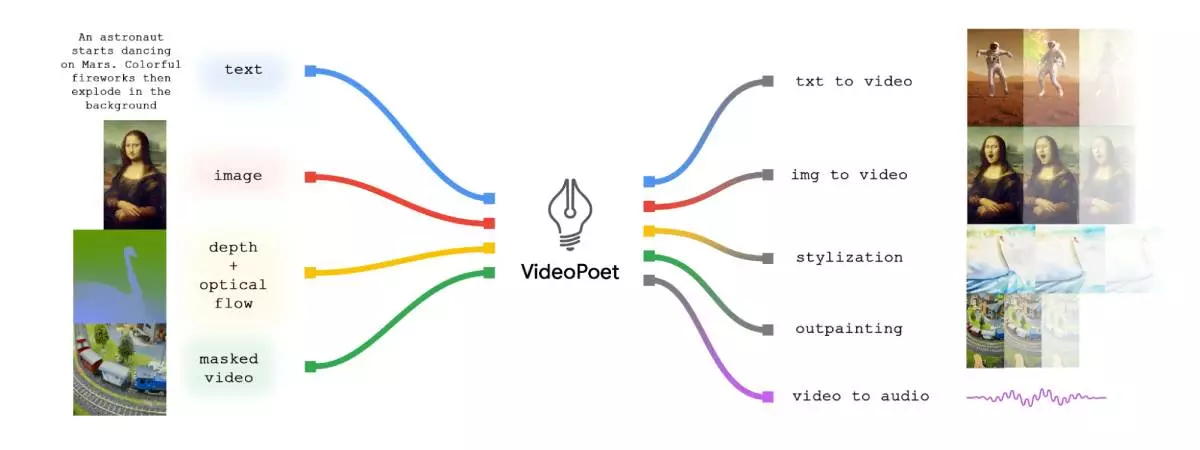
VideoPoet 是训练一个自回归语言模型,通过使用多个标记器(用于视频和图片的MAGVIT V2,以及用于语音的SoundStream)学习视频、图片、语音、文字形式,像是通过文字和图片输入分解、标记,进而产生复杂的视频。
Google 目标希望 VideoPoet 能够 any-to-any,根据任何提示任意转换,同时也要扩展至文字转成视频、语音转成视频、生成视频字幕等功能。
VideoPoet 将许多视频生成功能无缝整合至单一模型,而不是针对不同任务单独训练模型,特别在生成有趣影片和高品质动作上,展现出大型语言模型具高度竞争力的视频生成品质。